title: brpc框架学习之负载均衡模块
date: 2018-08-08 09:59:48
tags:
简介
后台服务往往都是以集群的方式来提供服务,从而使处理请求的压力得到提升,也避免了单点故障等问题。因为架构的分层,服务一般都会有上游服务和下游服务,在经典的三层架构中,业务逻辑层上游是接入层,下游是db层。当服务访问下层服务时,需要连接服务集群,这里概念涉及两个:命名服务和负载均衡
命名服务
命名服务把一个名字映射为可修改的机器列表,在client端的位置如下: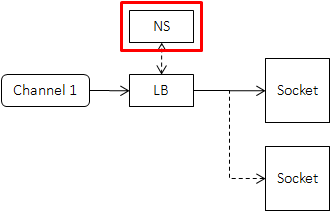
有了命名服务后client记录的是一个名字,而不是每一台下游机器。而当下游机器变化时,就只需要修改命名服务中的列表,而不需要逐台修改每个上游。这个过程也常被称为“解耦上下游”。当然在具体实现上,上游会记录每一台下游机器,并定期向命名服务请求或被推送最新的列表,以避免在RPC请求时才去访问命名服务。使用命名服务一般不会对访问性能造成影响,对命名服务的压力也很小。
负载均衡
当下游机器超过一台时,我们需要分割流量,此过程一般称为负载均衡,在client端的位置如下图所示: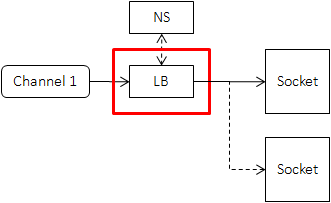
理想的算法是每个请求都得到及时的处理,且任意机器crash对全局影响较小。但由于client端无法及时获得server端的延迟或拥塞,而且负载均衡算法不能耗费太多的cpu,一般来说用户得根据具体的场景选择合适的算法
brpc中负载模块框架
整体uml图
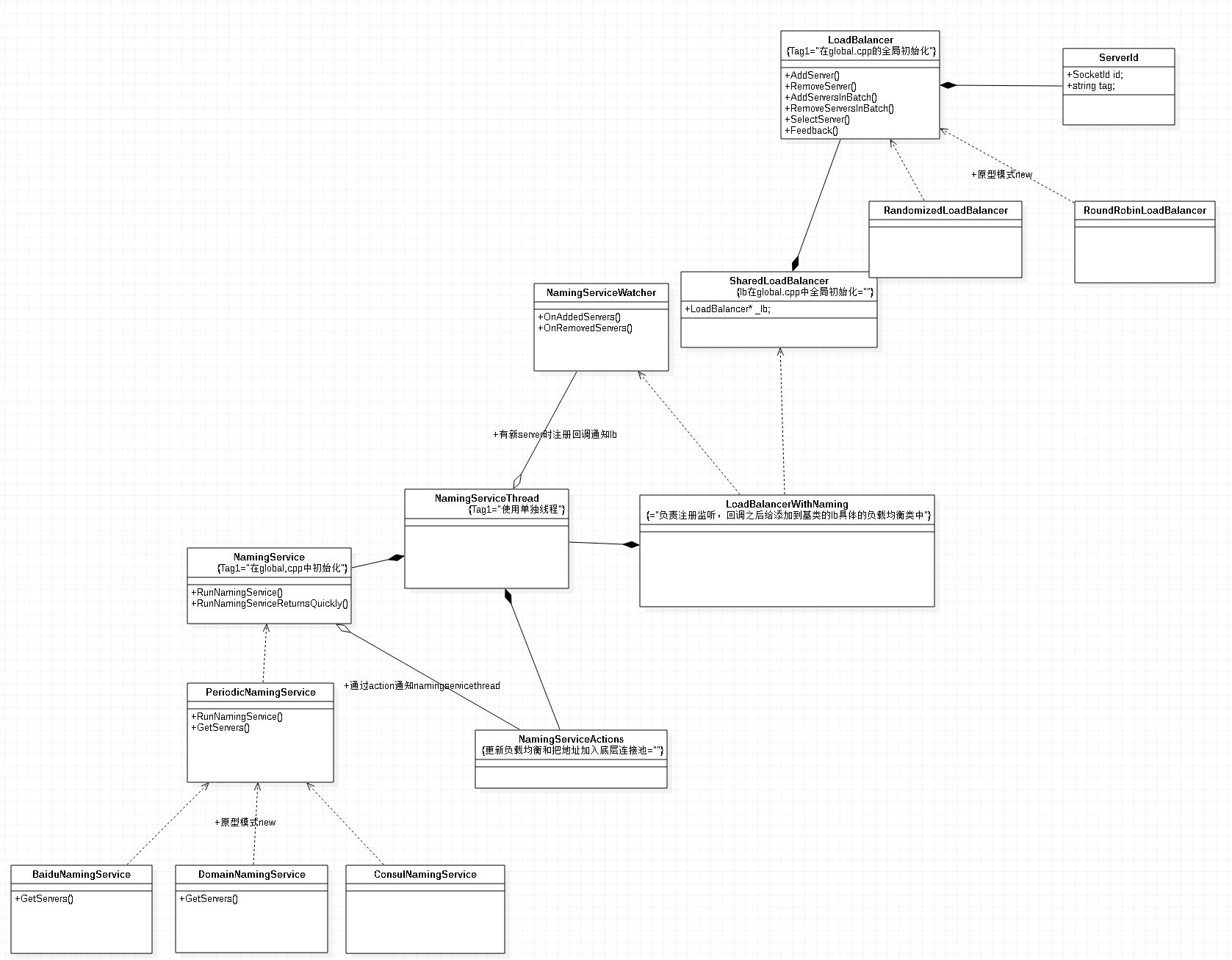
代码详解
命令服务和负载均衡的基础类框架
brpc中的命名服务类和负载均衡类在global.cpp中初始化,结构体GlobalExtensions中包含了所有命名服务和负载均衡的实例,在GlobalInitializeOrDieImpl函数中,将GlobalExtensions中的所有实例注册到NamingServiceExtension和LoadBalancerExtension中。如下所示:
```c++
NamingServiceExtension()->RegisterOrDie("bns", &g_ext->bns);
NamingServiceExtension()->RegisterOrDie("file", &g_ext->fns);
NamingServiceExtension()->RegisterOrDie("list", &g_ext->lns);
NamingServiceExtension()->RegisterOrDie("http", &g_ext->dns);
NamingServiceExtension()->RegisterOrDie("remotefile", &g_ext->rfns);
NamingServiceExtension()->RegisterOrDie("consul", &g_ext->cns);
// Load Balancers
LoadBalancerExtension()->RegisterOrDie("rr", &g_ext->rr_lb);
LoadBalancerExtension()->RegisterOrDie("wrr", &g_ext->wrr_lb);
LoadBalancerExtension()->RegisterOrDie("random", &g_ext->randomized_lb);
LoadBalancerExtension()->RegisterOrDie("la", &g_ext->la_lb);
LoadBalancerExtension()->RegisterOrDie("c_murmurhash", &g_ext->ch_mh_lb);
LoadBalancerExtension()->RegisterOrDie("c_md5", &g_ext->ch_md5_lb);
LoadBalancerExtension()->RegisterOrDie("_dynpart", &g_ext->dynpart_lb);
```
这两个类使用单例模式,全局可以统一访问。所有命名服务的基类是NamingService,负载均衡类是LoadBalancer。这两个类的基类中都实现了New函数
```c++
virtual T* New() const = 0;
```
这里使用了原型模式,每次创建一个client客户端需要使用命名服务时,根据NamingServiceExtension注册的命名找到对应的服务类,调用服务类的New函数构建出一个实例
调用框架
LoadBalancerWithNaming类是brpc中使用负载均衡的实例类,在整体上,相当于契合了命名服务和负载均衡,负载均衡和命名服务交互的中间层,初始化时带上命名服务的url和负载均衡的名字
```c++
int Init(const char* ns_url, const char* lb_name, const NamingServiceFilter* filter, const GetNamingServiceThreadOptions* options)
{
if (SharedLoadBalancer::Init(lb_name) != 0) {
return -1;
}
if (GetNamingServiceThread(&_nsthread_ptr, ns_url, options) != 0) {
LOG(FATAL) << "Fail to get NamingServiceThread";
return -1;
}
if (_nsthread_ptr->AddWatcher(this, filter) != 0) {
LOG(FATAL) << "Fail to add watcher into _server_list";
return -1;
}
return 0;
}
```
LoadBalancerWithNaming的基类SharedLoadBalancer在init中根据传入的lb_name会实例化一个LoadBalancer类
```c++
int SharedLoadBalancer::Init(const char* lb_name) {
const LoadBalancer* lb = LoadBalancerExtension()->Find(lb_name);
if (lb == NULL) {
LOG(FATAL) << "Fail to find LoadBalancer by `" << lb_name << "'";
return -1;
}
LoadBalancer* lb_copy = lb->New();
if (lb_copy == NULL) {
LOG(FATAL) << "Fail to new LoadBalancer";
return -1;
}
_lb = lb_copy;
if (FLAGS_show_lb_in_vars && !_exposed) {
ExposeLB();
}
return 0;
}
```
接着调用GetNamingServiceThread获取一个ns线程
GetNamingServiceThread函数:
- 首先根据ns_url找到对应的命名服务类ns
- 以ns的地址和ns_usl解析出的服务地址做为key,查找全局变量g_nsthread_map中是否已经有相关的ns线程,如果没有则创建一个并调用nsThread的start函数,有则不再新建直接返回这个nsThread
- 将LoadBalancerWithNaming注册到nsThread中实现托管,到nsThread中ns的ip变化时会通知LoadBalancerWithNaming
- nsThread调用LoadBalancerWithNaming::OnAddedServers通知已经注册的ip,LoadBalancerWithNaming将其添加到LoadBalancer中
当服务需要把信息发送给下游时,调用LoadBalancerWithNaming::SelectServer返回一个socket
NamingServiceThread调用命名服务详解详解
NamingServiceThread::Start函数
- 根据ns实例调用其New接口复制一个实例
- 如果这个ns支持快速获取ip,则直接调用ns的RunNamingService接口,如果不支持快速调用则另起一个线程任务调用此接口,原线程等待其完成。这里注意的是,之所以要另起线程,是因为新起线程可能一直在重复获取下游ip的操作,而有返回ip值了原线程就会结束等待。
ns的接口很简单,如下:
```c++
class NamingService
{
// 运行获取ip
virtual int RunNamingService(const char* service_name, NamingServiceActions* actions) = 0;
// 该命运服务是否支持快速返回,一般本地列表不需要网络请求的可以打开
virtual bool RunNamingServiceReturnsQuickly() { return false; }
virtual NamingService* New() const = 0;
}
```
在brpc中使用long polling长轮询来实现命名服务的更新(当然有些并不是长轮询而是轮询,比如http命名服务),这里解释一下长轮询
说到Long Polling(长轮询),必然少不了提起Polling(轮询),这都是客户端拉取服务器模式的两种方式。
Polling是指不管服务端数据有无更新,客户端每隔定长时间请求拉取一次数据,可能有更新数据返回,也可能什么都没有。
Long Polling原理也很简单,相比Polling,客户端发起Long Polling,此时如果服务端没有相关数据,会hold住请求,直到服务端有相关数据,或者等待一定时间超时才会返回。返回后,客户端又会立即再次发起下一次Long Polling。这种方式也是对拉模式的一个优化,解决了拉模式数据通知不及时,以及减少了大量的无效轮询次数。(所谓的hold住请求指的服务端暂时不回复结果,保存相关请求,不关闭请求连接,等相关数据准备好,写会客户端。)
前面提到Long Polling如果当时服务端没有需要的相关数据,此时请求会hold住,直到服务端把相关数据准备好,或者等待一定时间直到此次请求超时,这里大家是否有疑问,为什么不是一直等待到服务端数据准备好再返回,这样也不需要再次发起下一次的Long Polling,节省资源?
主要原因是网络传输层主要走的是tcp协议,tcp协议是可靠面向连接的协议,通过三次握手建立连接。但是所建立的连接是虚拟的,可能存在某段时间网络不通,或者服务端程序非正常关闭,亦或服务端机器非正常关机,面对这些情况客户端根本不知道服务端此时已经不能互通,还在傻傻的等服务端发数据过来,而这一等一般都是很长时间。当然tcp协议栈在实现上有保活计时器来保证的,但是等到保活计时器发现连接已经断开需要很长时间,如果没有专门配置过相关的tcp参数,一般需要2个小时,而且这些参数是机器操作系统层面,所以,以此方式来保活不太靠谱,故Long Polling的实现上一般是需要设置超时时间的。
因此,需要网络通信的命名服务,大多继承自PeriodicNamingService类,PeriodicNamingService类继承NamingService并实现了RunNamingService,定期去访问(默认是5s),如下所示
```c++
int PeriodicNamingService::RunNamingService(
const char* service_name, NamingServiceActions* actions) {
std::vector<ServerNode> servers;
bool ever_reset = false;
for (;;) {
servers.clear();
const int rc = GetServers(service_name, &servers); // 该接口由各个派生类自己实现
if (rc == 0) {
ever_reset = true;
actions->ResetServers(servers);
} else if (!ever_reset) {
// ResetServers must be called at first time even if GetServers
// failed, to wake up callers to `WaitForFirstBatchOfServers'
ever_reset = true;
servers.clear();
actions->ResetServers(servers);
}
if (bthread_usleep(std::max(FLAGS_ns_access_interval, 1) * 1000000L) < 0) {
if (errno == ESTOP) {
RPC_VLOG << "Quit NamingServiceThread=" << bthread_self();
return 0;
}
PLOG(FATAL) << "Fail to sleep";
return -1;
}
}
}
```
nsThread和ns的通信NamingServiceActions
从上面RunNamingService函数可以看到,当获取到ip地址时,则调用actions->ResetServers接口,该实例是NamingServiceThread类中的Actions,这里做了很多事情
- 将serves数组中的ip列表复制到_servers成员变量中
- 对_servers进行排序去重
- 上一次的结果记录在_last_servers中,_added中做_servers和_last_servers的交集,得到_servers存在_last_servers不存在的ip
- _removed做_servers和_last_servers的交集,得到_servers不存在_last_servers存在的ip
- 将_added中的所有ip建立连接得到套接字push到_added_sockets中
- 根据_removed取出所有需要移除的套接字计入到_removed_sockets中
- 调用注册在NamingServiceThread上的所有LoadBalancerWithNaming,调用他们的OnRemovedServers和OnAddedServers通知新增的ip和要移除的ip,LoadBalancerWithNaming会调用相绑定的负载均衡实例
- 断开需要移除的套接字的连接
- 将移除的ip输出log
- 打开_wait_id让外界结束等待
LoadBalancer负载均衡基类详解
```c++
class LoadBalancer
{
//下面这两个很少用,实际都是用下batch版本
virtual bool AddServer(const ServerId& server) = 0;
virtual bool RemoveServer(const ServerId& server) = 0;
virtual size_t AddServersInBatch(const std::vector<ServerId>& servers) = 0;
virtual size_t RemoveServersInBatch(const std::vector<ServerId>& servers) = 0;
//返回一个服务
virtual int SelectServer(const SelectIn& in, SelectOut* out) = 0;
//rpc调用完成之后调用此接口返回一些统计信息
virtual void Feedback(const CallInfo& /*info*/) { }
vrtual LoadBalancer* New() const = 0;
}
```
具体实现类中,数据的添加删除修改也非常有参考意义
brpc中的命名服务类型
naming_service_url的一般形式是”protocol://service_name” 如使用http命名服务则是:http://www.chennhuang.com:8000。示例echo_client启动附带参数:
```c++
--server=http://www.chennhuang.com:8000 --load_balancer=random
```
bns://(bns-name)
BNS是百度内常用的命名服务,比如bns://rdev.matrix.all,其中”bns”是protocol,”rdev.matrix.all”是service-name
```c++
class BaiduNamingService : public PeriodicNamingService
```
bns命名服务继承PeriodicNamingService,前面说过PeriodicNamingService定期(最小1s,默认5s)调用GetServers接口,bns服务实现了该接口。该接口实现了调用了baidu的内部库,这里看不到相关实现,推测是使用了长轮询
file://(path)
服务器列表放在path所在的文件里,比如”file://conf/machine_list”中的“conf/machine_list”对应一个文件:
每行是一台服务器的地址。
地址后出现的非注释内容被认为是tag,由一个或多个空格与前面的地址分隔,相同的地址+不同的tag被认为是不同的实例。
当文件更新时, brpc会重新加载。
10.24.234.17 tag1 # 这是注释,会被忽略
10.24.234.17 tag2 # 此行和上一行被认为是不同的实例
10.24.234.18
10.24.234.19
优点: 易于修改,方便单测。
缺点: 更新时需要修改每个上游的列表文件,不适合线上部署。
```c++
class FileNamingService : public NamingService
```
filename因为不用定期轮询(或长轮询),所以直接继承NamingService,且该服务会监控文件是否有变化
```c++
int FileNamingService::RunNamingService(const char* service_name,
NamingServiceActions* actions) {
std::vector<ServerNode> servers;
butil::FileWatcher fw;
if (fw.init(service_name) < 0) {
LOG(ERROR) << "Fail to init FileWatcher on `" << service_name << "'";
return -1;
}
for (;;) {
const int rc = GetServers(service_name, &servers);
if (rc != 0) {
return rc;
}
actions->ResetServers(servers);
for (;;) {
butil::FileWatcher::Change change = fw.check_and_consume();
if (change > 0) {
break;
}
if (change < 0) {
LOG(ERROR) << "`" << service_name << "' was deleted";
}
if (bthread_usleep(100000L/*100ms*/) < 0) {
if (errno == ESTOP) {
return 0;
}
PLOG(ERROR) << "Fail to sleep";
return -1;
}
}
}
CHECK(false);
return -1;
}
```
http://(url)
连接一个域名下所有的机器, 例如http://www.baidu.com:80 ,注意连接单点的Init(两个参数)虽然也可传入域名,但只会连接域名下的一台机器。
优点: DNS的通用性,公网内网均可使用。
缺点: 受限于DNS的格式限制无法传递复杂的meta数据,也无法实现通知机制。
```c++
DomainNamingService : public PeriodicNamingService
```
其循环调用gethostbyname_r获取该域名下的所有ip,这种方式是使用轮询。
list://(addr1),(addr2)
服务器列表直接跟在list://之后,以逗号分隔,比如”list://db-bce-81-3-186.db01:7000,m1-bce-44-67-72.m1:7000,cp01-rd-cos-006.cp01:7000”中有三个地址。
地址后可以声明tag,用一个或多个空格分隔,相同的地址+不同的tag被认为是不同的实例。
优点: 可在命令行中直接配置,方便单测。
缺点: 无法在运行时修改,完全不能用于线上部署。
remotefile://(path)
貌似很少应用这种,不讲。
consul://(service-name)
通过consul获取服务名称为service-name的服务列表。consul的默认地址是localhost:8500,可通过gflags设置-consul_agent_addr来修改。consul的连接超时时间默认是200ms,可通过-consul_connect_timeout_ms来修改。
默认在consul请求参数中添加stale和passing(仅返回状态为passing的服务列表),可通过gflags中-consul_url_parameter改变consul请求参数。
除了对consul的首次请求,后续对consul的请求都采用long polling的方式,即仅当服务列表更新或请求超时后consul才返回结果,这里超时时间默认为60s,可通过-consul_blocking_query_wait_secs来设置。
若consul返回的服务列表响应格式有错误,或者列表中所有服务都因为地址、端口等关键字段缺失或无法解析而被过滤,consul naming server会拒绝更新服务列表,并在一段时间后(默认500ms,可通过-consul_retry_interval_ms设置)重新访问consul。
如果consul不可访问,服务可自动降级到file naming service获取服务列表。此功能默认关闭,可通过设置-consul_enable_degrade_to_file_naming_service来打开。服务列表文件目录通过-consul _file_naming_service_dir来设置,使用service-name作为文件名。该文件可通过consul-template生成,里面会保存consul不可用之前最新的下游服务节点。当consul恢复时可自动恢复到consul naming service。主要是考虑consul不可用时,服务进程又恰好发生重启的场景。其中,服务节点列表文件也是会通过consul自动更新的,里面会保存consul不可用之前最新的下游服务节点。
brpc中的负载均衡服务类型
rr方式
轮询(Round Robbin)当服务器群中各服务器的处理能力相同时,且每笔业务处理量差异不大时,最适合使用这种算法。 轮循,按公约后的权重设置轮循比率。存在慢的提供者累积请求问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上
wrr方式
加权轮询(Weighted Round Robbin)为轮询中的每台服务器附加一定权重的算法。比如服务器1权重1,服务器2权重2,服务器3权重3,则顺序为1-2-2-3-3-3-1-2-2-3-3-3-
random方式
随机从列表中选择一台服务器,无需其他设置。和round robin类似,这个算法的前提也是服务器都是类似的。按权重设置随机概率,在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重
la方式
c_murmurhash or c_md5方式
最小连接及加权最小连接(非brpc中实现)
最少连接(Least Connections)在多个服务器中,与处理连接数(会话数)最少的服务器进行通信的算法。即使在每台服务器处理能力各不相同,每笔业务处理量也不相同的情况下,也能够在一定程度上降低服务器的负载。
加权最少连接(Weighted Least Connection)为最少连接算法中的每台服务器附加权重的算法,该算法事先为每台服务器分配处理连接的数量,并将客户端请求转至连接数最少的服务器上。
IP地址散列(非brpc中实现)
通过管理发送方IP和目的地IP地址的散列,将来自同一发送方的分组(或发送至同一目的地的分组)统一转发到相同服务器的算法。当客户端有一系列业务需要处理而必须和一个服务器反复通信时,该算法能够以流(会话)为单位,保证来自相同客户端的通信能够一直在同一服务器中进行处理。
URL散列(非brpc中实现)
通过管理客户端请求URL信息的散列,将发送至相同URL的请求转发至同一服务器的算法。